網羅的にレビューするワークフローを作成する
本ページでは、複数のドキュメントを対象に、網羅的かつ安定したレビューを実施するためのワークフローの作成方法を解説します。
ワークフローを利用する目的
単一のAIエージェントによるレビューでは、以下のような課題が発生します。
- 大量のドキュメントを一度に処理できない
- レビュー観点の抜け漏れが発生する
- 回答の安定性が低下する
ワークフローを活用することで、これらの課題を解決し、レビュー処理を分割・自動化することができます。
今回のゴール
指定フォルダ配下のドキュメントを対象に、章単位で分割し、AIエージェントによるレビューを自動的に実行するワークフローを構築します。
ワークフローの処理の流れ
本ワークフローでは、以下の処理を実行します。
- 対象フォルダの一覧取得
- フォルダ内のファイル一覧取得
- ドキュメントの構造化
- 章単位への分割
- 各章ごとのレビュー実行
このように処理を分割することで、大規模ドキュメントでも安定したレビューが可能になります。
事前準備
レビュー対象となるドキュメントを格納したフォルダを用意してください。
データのダウンロードと格納方法は、「サンプルデータの環境構築方法」を参照ください。
1. ワークフローを作成する
-
ワークフロー編集画面を開きます。
-
レビュー対象の親フォルダを変数に設定します。
ワークフロータイトル横の[ワークフロー設定] - [入出力パラメータ] - [入力パラメータ]より、ワークフローで利用するレビュー対象の親フォルダを登録してください。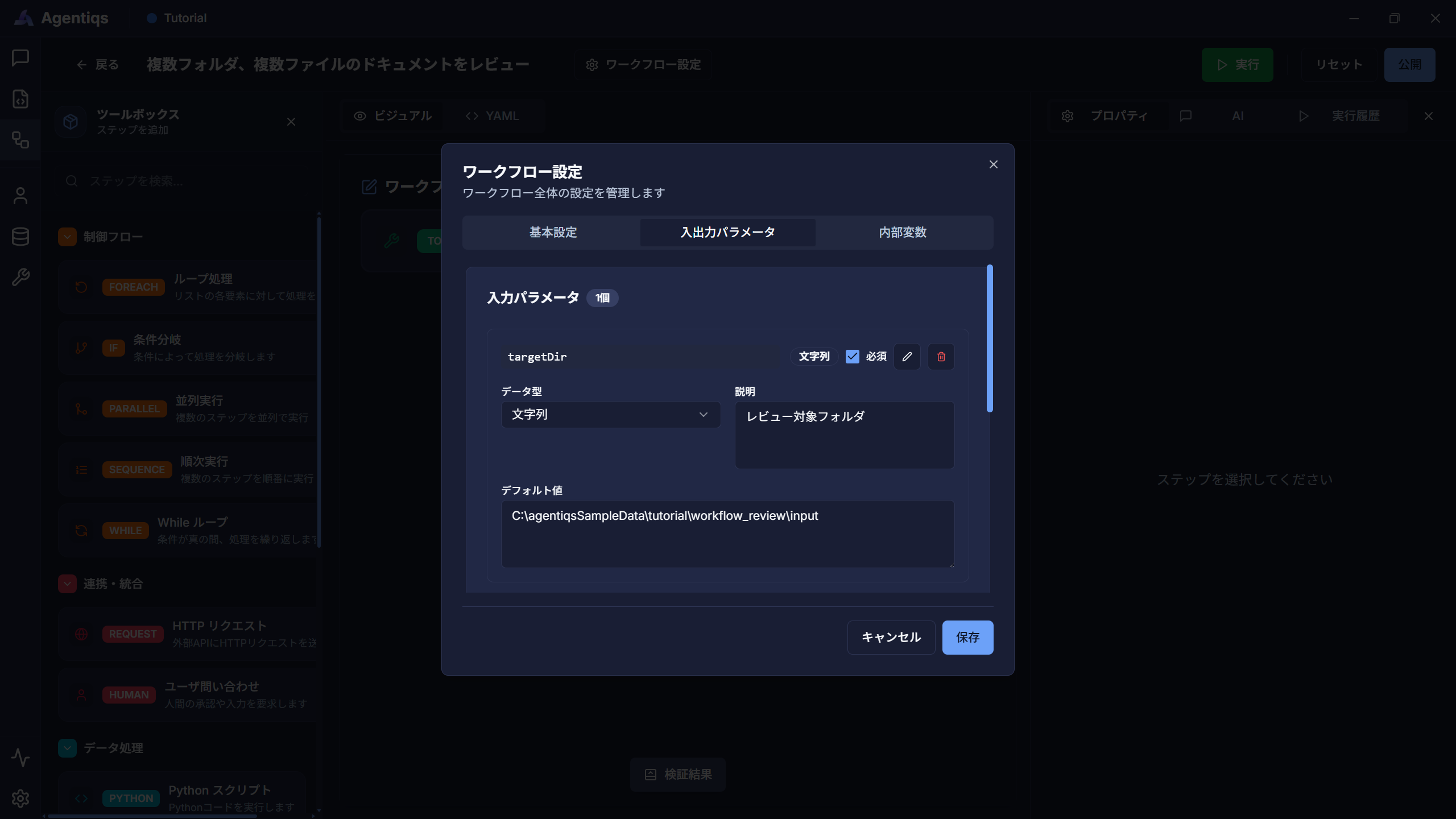 レビュー対象のファイルが入っているフォルダをすべて取得できるようになります。
レビュー対象のファイルが入っているフォルダをすべて取得できるようになります。 -
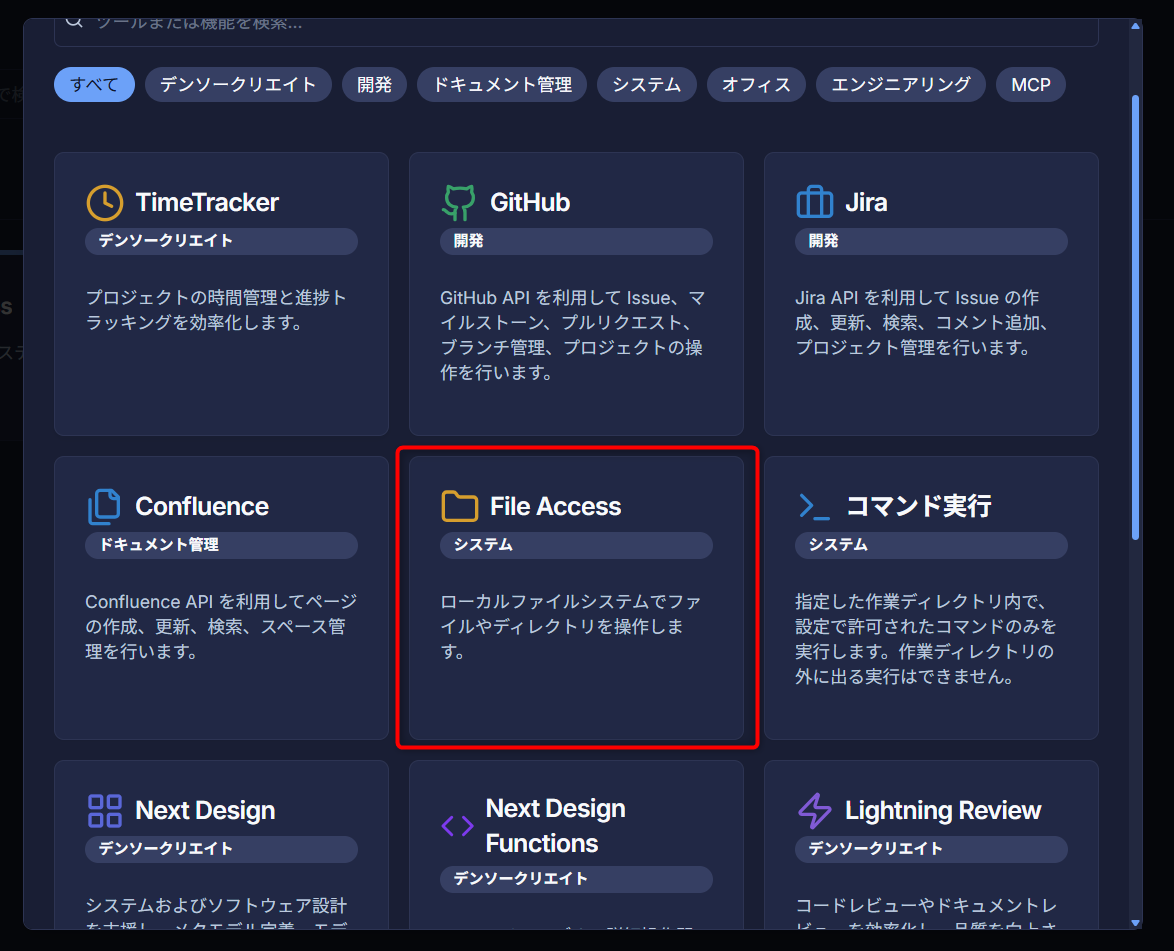
利用するツールを作成します。
ツールタブより[新規作成] - [FileAccess] を選択してください。
 備考
備考他の用途で「FileAccess」を作成していても、指定するベースディレクトリが異なる場合は新しく作成してください。
(FileAccessツールの名前は適切に設定してください。) -
FileAccessの[設定] - [ベースディレクトリ]にディレクトリのパスを設定します。
このツールを使って操作するディレクトリを指定してください。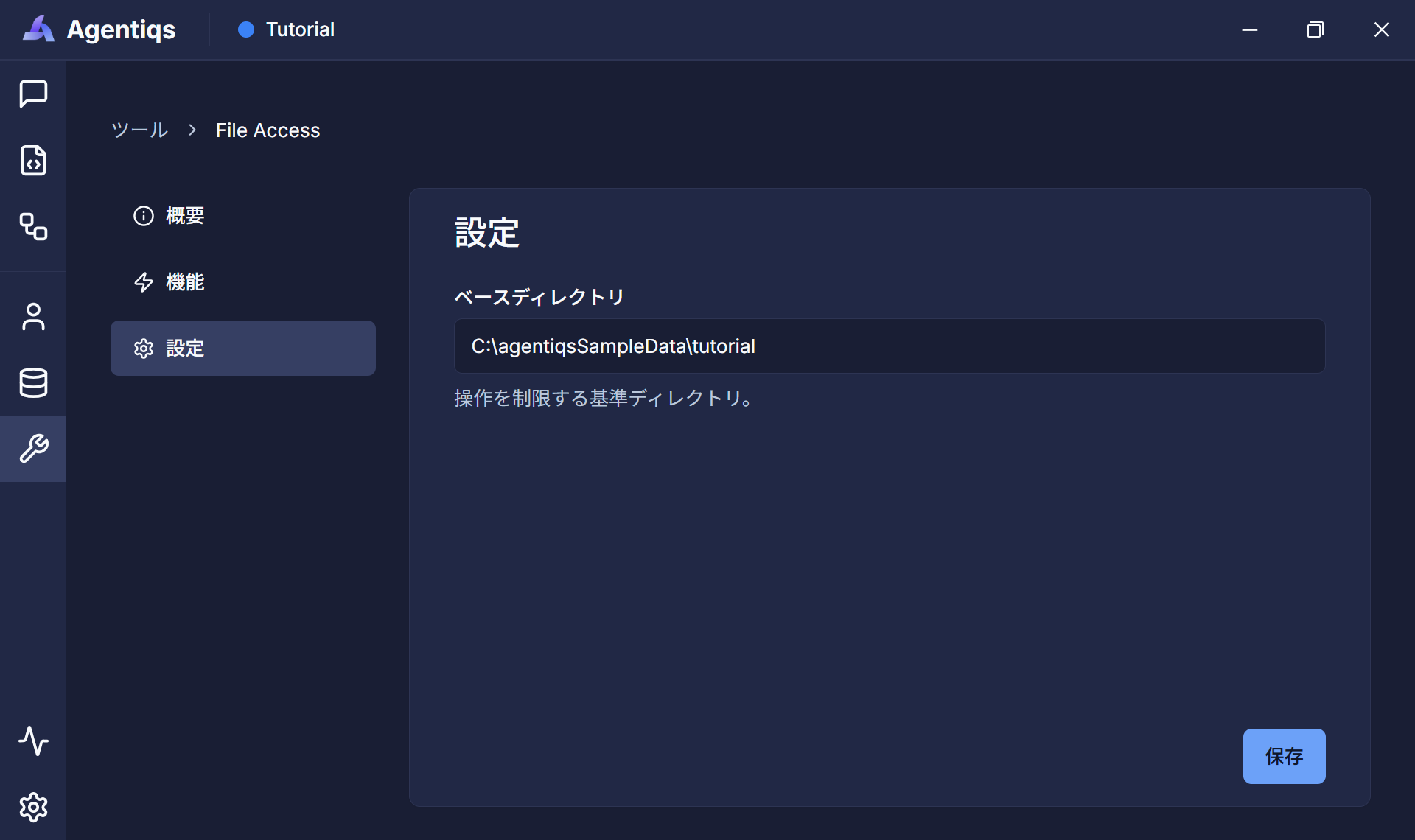
-
ファイルを読み込む処理を設定します。
ワークフローの画面に戻り、左側ツールボックスより"ツール実行"を、ドラッグ&ドロップで初めのステップとして設定してください。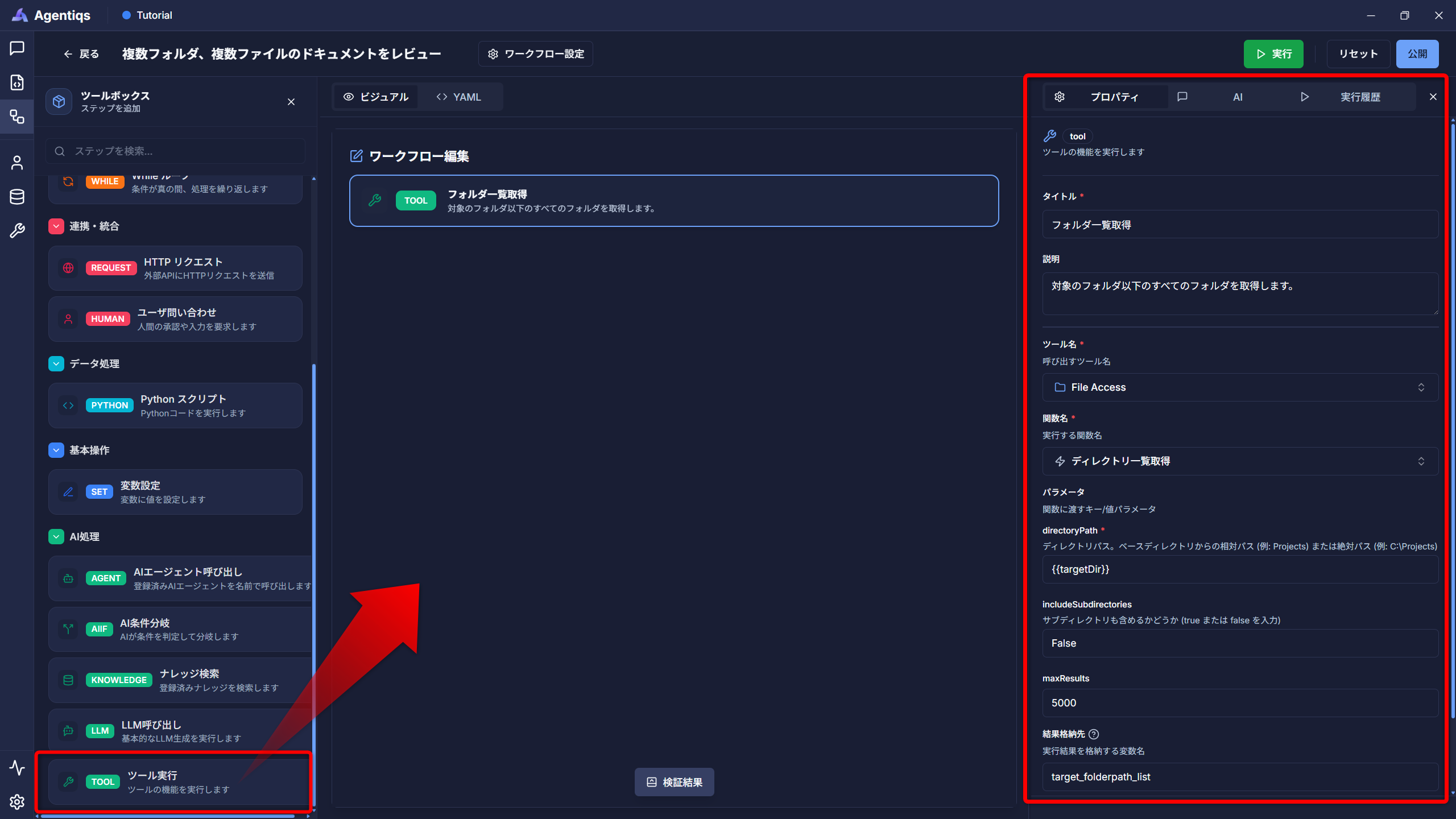
ステップで実行する処理を、画面右側の赤枠(プロパティ)に入力してください。
プロパティの設定項目
指定したフォルダ配下にあるフォルダの一覧を取得し、「target_folderpath_list」に格納します。
プロパティ 必須 設定項目 詳細説明 タイトル タイトル 後から判別できる、わかりやすい名前にしてください。 説明 ステップで実施する内容 ツール名 〇 手順3で作成したツール 関数名 〇 「ディレクトリ一覧取得」 このノードではフォルダ一覧を取得するためです。 directoryPath 〇 手順4で登録したパス 変数{x}から選択して登録します。 includeSubdirectories 〇 False サブフォルダも含めるか指定。今回は含めません。 結果格納先 〇 target_folderpath_list実行結果を変数に格納します。 この操作により、フォルダ一覧を取得できるようになります。
-
対象フォルダに格納されたファイルに対するループ処理を設定します。
"ループ処理"をドラッグ&ドロップで配置し、プロパティを設定してください。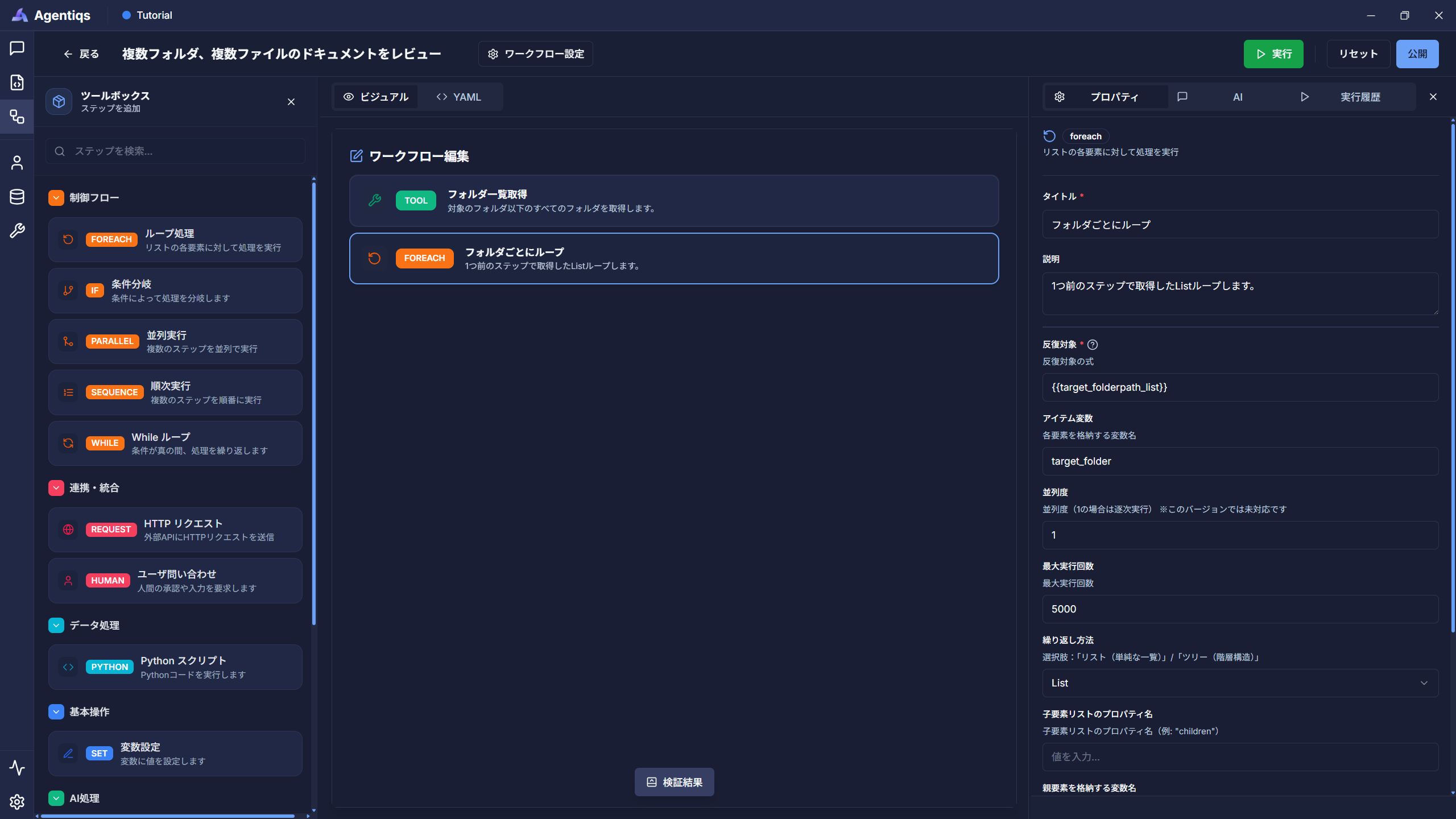
プロパティの設定項目
前のステップで取得したフォルダ一覧(target_folderpath_list)から1つフォルダを取得します。
(1フォルダずつ取得し、次ステップ以降の処理を繰り返し実施します)プロパティ 必須 設定項目 詳細説明 タイトル タイトル 後から判別できる、わかりやすい名前にしてください。 説明 ステップで実施する内容 反復対象 〇 {{target_folderpath_list}}ループ対象のリストデータを渡します。(手順5の出力) アイテム変数 〇 target_folderループで実行する処理で利用する名前(次ステップで利用) 最大実行回数 〇 例:5000 回数が多いと時間がかかるため、デバッグ時は2~5回を指定。 -
フォルダ以下に格納されているファイル一覧を取得します。
"ツール実行"をドラッグ&ドロップでループの子要素として配置し、プロパティを設定します。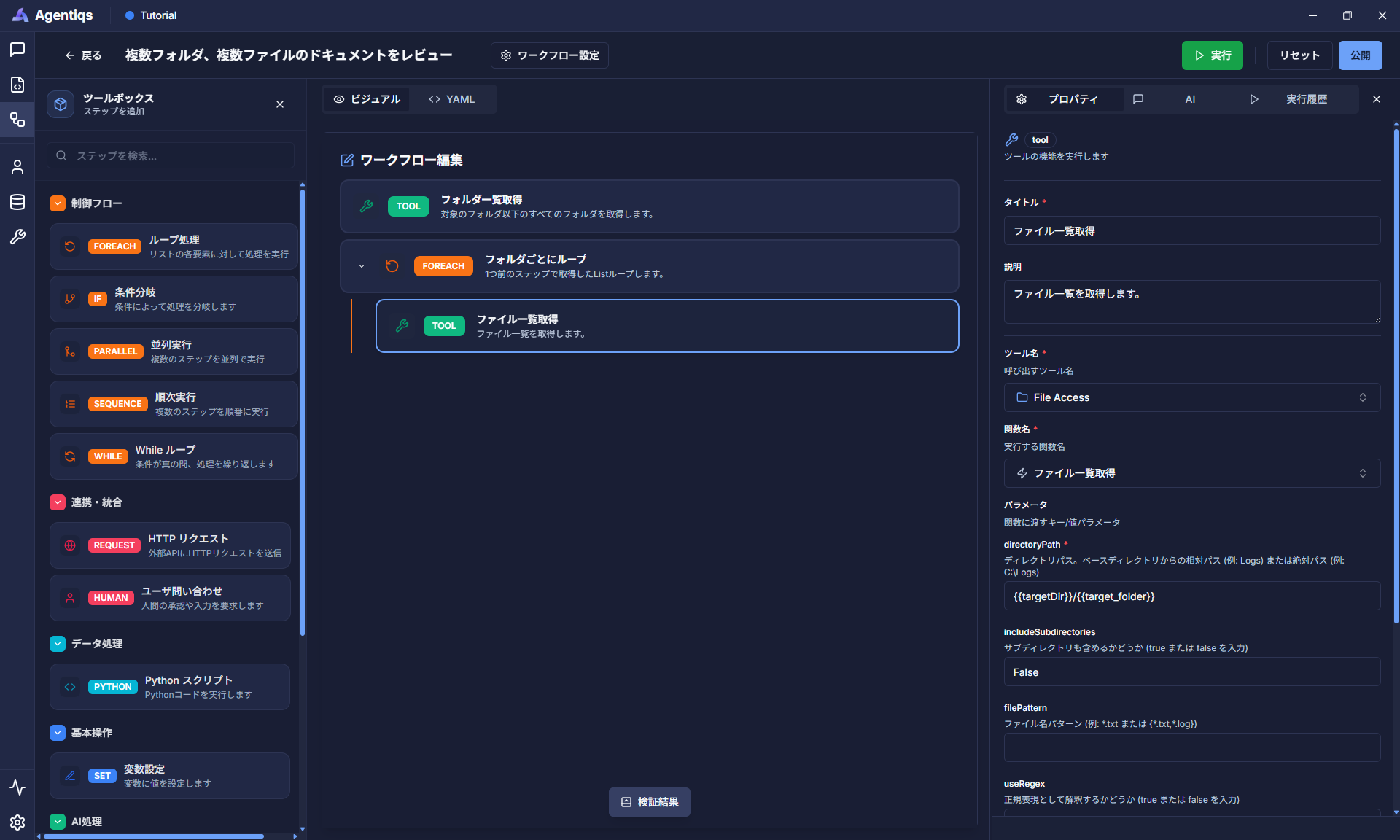
プロパティの設定項目
フォルダ内に含まれるファイルのうち、拡張子が「.docx」のファイルを「target_file_list」に格納します。
プロパティ 必須 設定項目 詳細説明 タイトル タイトル 後から判別できる、わかりやすい名前にしてください。 説明 ステップで実施する内容 ツール名 〇 手順3で作成したツール 関数名 〇 「ファイル一覧取得」 このノードではファイル一覧を取得します。 directoryPath 〇 {{targetDir}}/{{target_folder}}手順6で登録したパスを選択します。 includeSubdirectories 〇 False サブフォルダも含めるか指定。今回は含めません。 filePattern 例:*.docx 取得する拡張子を指定します。 結果格納先 〇 target_file_list実行結果を変数に格納します。 -
対象フォルダに格納されたファイルに対するループ処理を設定します。
"ループ処理"をドラッグ&ドロップで配置し、プロパティを設定してください。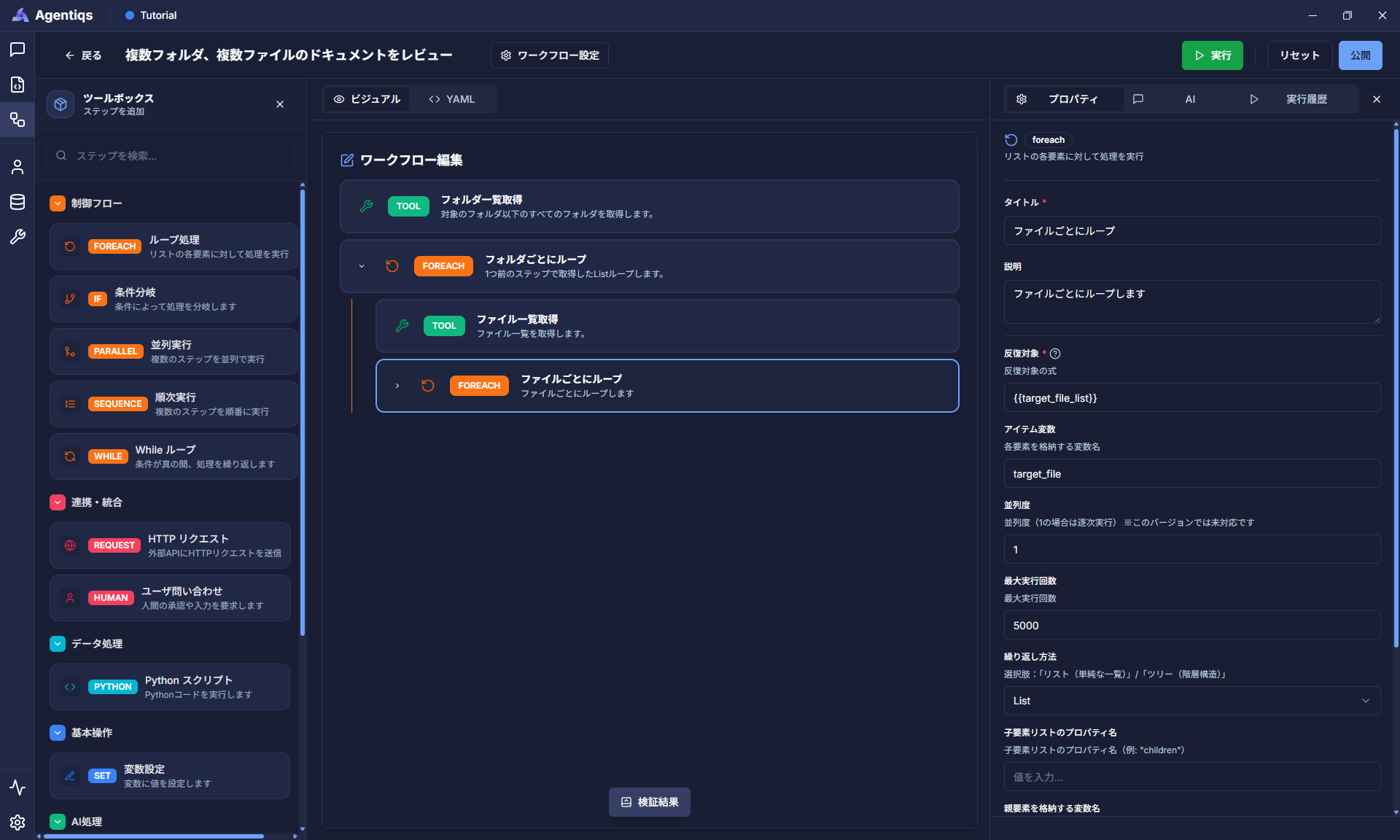
プロパティの設定項目
前のステップで取得したファイル一覧(target_file_list)から1つファイルを取得します。
(1ファイルずつ取得し、次ステップ以降の処理を繰り返し実施します)プロパティ 必須 設定項目 詳細説明 タイトル タイトル 後から判別できる、わかりやすい名前にしてください。 説明 ステップで実施する内容 反復対象 〇 {{target_file_list}}ループ対象のリストデータを渡します。(手順7の出力) アイテム変数 〇 target_fileループで実行する処理で利用する名前(次ステップで利用) 最大実行回数 〇 例:5000 回数が多いと時間がかかるため、デバッグ時は2~5回を指定。 -
ファイルのドキュメントを取得します。
"ツール実行"をドラッグ&ドロップでループの子要素として配置し、プロパティを設定してください。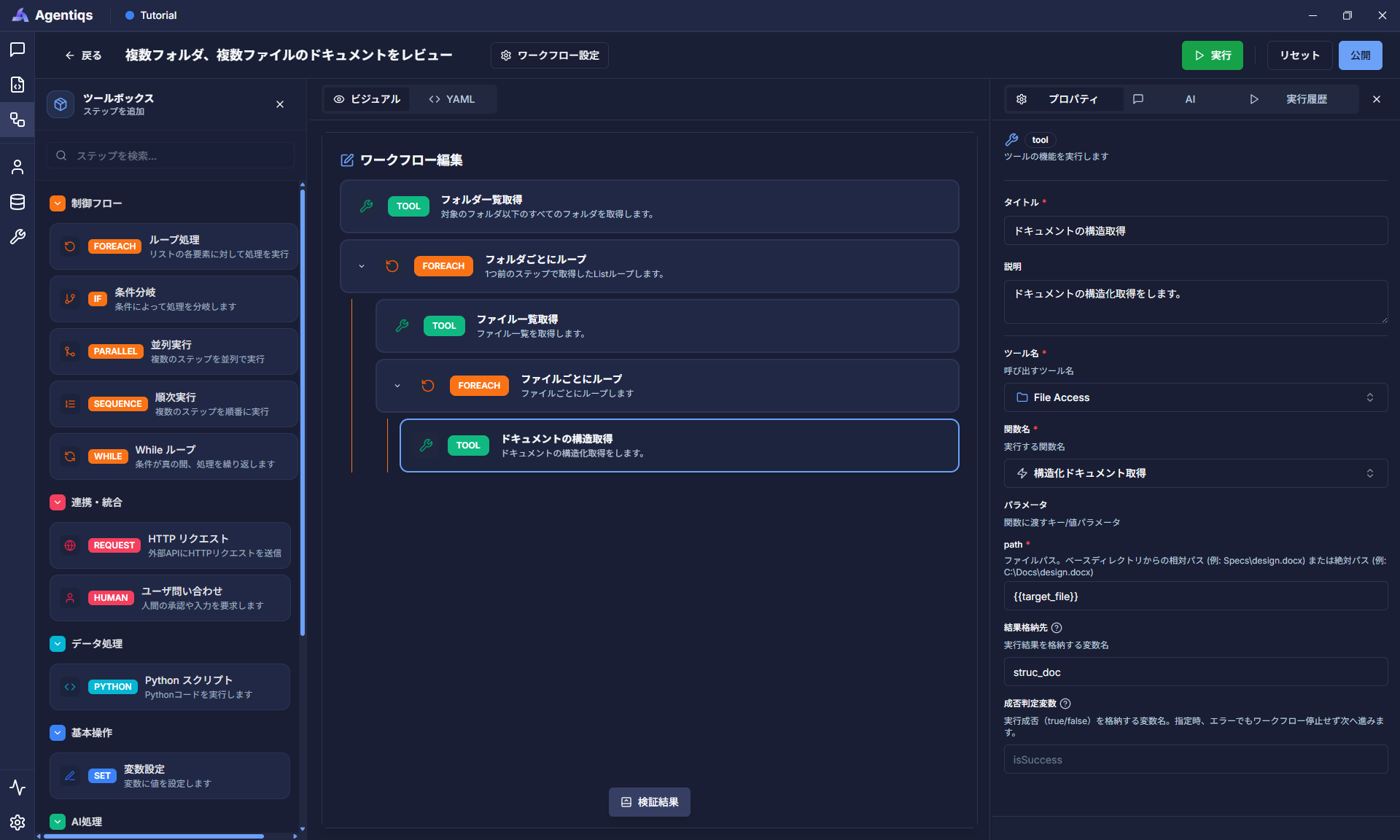
プロパティの設定項目
対象ファイルの章構造を取得します。
プロパティ 必須 設定項目 詳細説明 タイトル タイトル 後から判別できる、わかりやすい名前にしてください。 説明 ステップで実施する内容 ツール名 〇 手順3で作成したツール 関数名 〇 「構造化ドキュメント取得」(※) このノードではドキュメントを取得します。 Path 〇 {{target_file}}手順8で登録したパスを選択します。 結果格納先 〇 struc_doc実行結果を変数に格納します。 ※「ファイル内容取得」もありますが、今回は章ごとにレビューするため「構造化ドキュメント取得」を利用します。
-
構造化ドキュメントを分解し、章ごとにレビュー実施できるように整形します。
"Python スクリプト"をドラッグ&ドロップでループの子要素として配置し、プロパティを設定してください。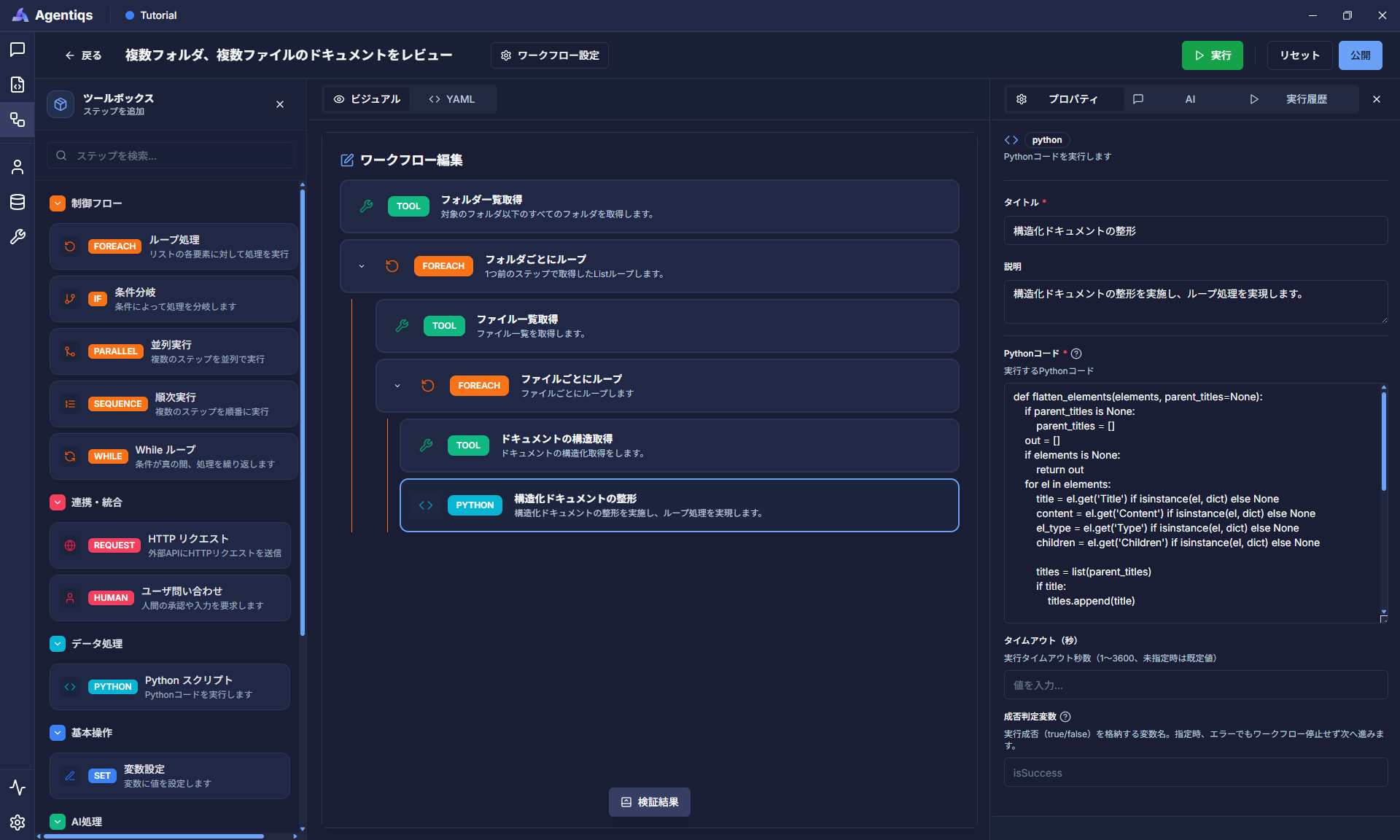
プロパティの設定項目
前ステップで取得したドキュメントの章一覧(階層構造)を、一覧形式のリストに変換するPythonプログラムを実行します。
プロパティ 必須 設定項目 詳細説明 タイトル タイトル 後から判別できる、わかりやすい名前にしてください。 説明 ステップで実施する内容 Pythonコード 〇 以下のコードを貼り付ける def flatten_elements(elements, parent_titles=None):if parent_titles is None:parent_titles = []out = []if elements is None:return outfor el in elements:title = el.get('Title') if isinstance(el, dict) else Nonecontent = el.get('Content') if isinstance(el, dict) else Noneel_type = el.get('Type') if isinstance(el, dict) else Nonechildren = el.get('Children') if isinstance(el, dict) else Nonetitles = list(parent_titles)if title:titles.append(title)out.append({'chapterPath': ' / '.join(titles) if titles else '(no title)','title': title or '(no title)','type': el_type or '','content': content or ''})if children:out.extend(flatten_elements(children, titles))return outsd = vars.struc_docelements = Noneif isinstance(sd, dict):elements = sd.get('Elements')chapters = flatten_elements(elements)vars.chapters = chapters -
構造化ドキュメントを章ごとにループします。
"ループ処理"をドラッグ&ドロップでループの子要素として配置し、プロパティを設定してください。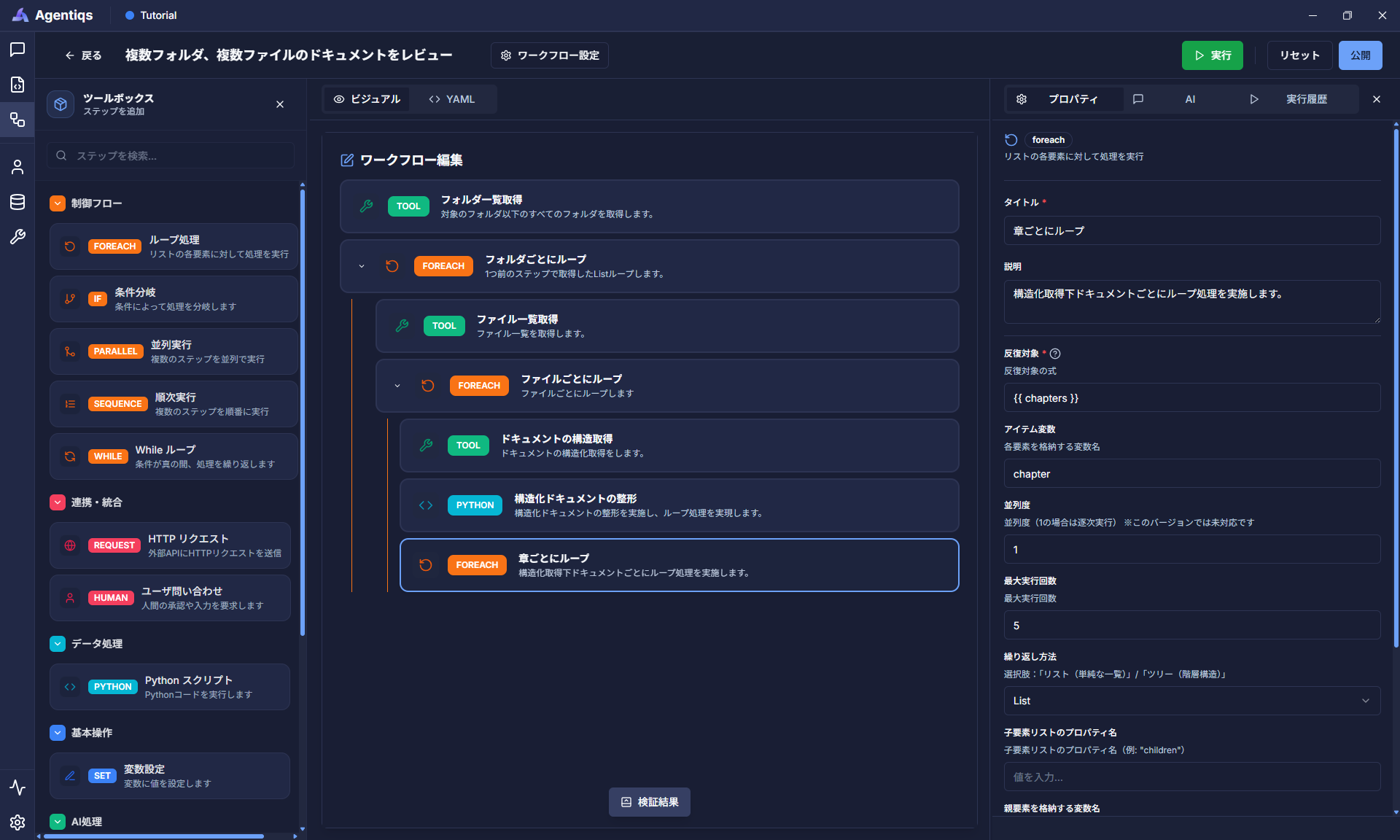
プロパティの設定項目
前のステップで取得した章の一覧(chapters)から1つの章を取得します。
(1章ずつ取得し、次ステップ以降の処理を繰り返し実施します)プロパティ 必須 設定項目 詳細説明 タイトル タイトル 後から判別できる、わかりやすい名前にしてください。 説明 ステップで実施する内容 反復対象 〇 {{ chapters }}ループ対象のリストデータを渡します。(手順10の出力) アイテム変数 〇 chapterループで実行する処理で利用する名前(次ステップで利用) 最大実行回数 〇 5 回数が多いと時間がかかるため、2~5回を指定。
多くの章を確認したい場合は 5,000 など大きな数にする。 -
次は、章ごとにレビューエージェントを呼び出して、出力します。
まずレビューを実施する専門のAIエージェントを作成します。今回はサンプルであるため、以下の処理とします。- レビュー結果をExcelやMD等様々な形式で出力できるようにするため、JSON形式で出力させます。
- システムプロンプトでレビュー観点を定義します。
→ より網羅的にレビューを実施する場合は、レビュー観点ごとにさらにループを定義してください。
[エージェント]タブ - [新規作成] から空のAIエージェントを選択し、各種設定値を設定してください。
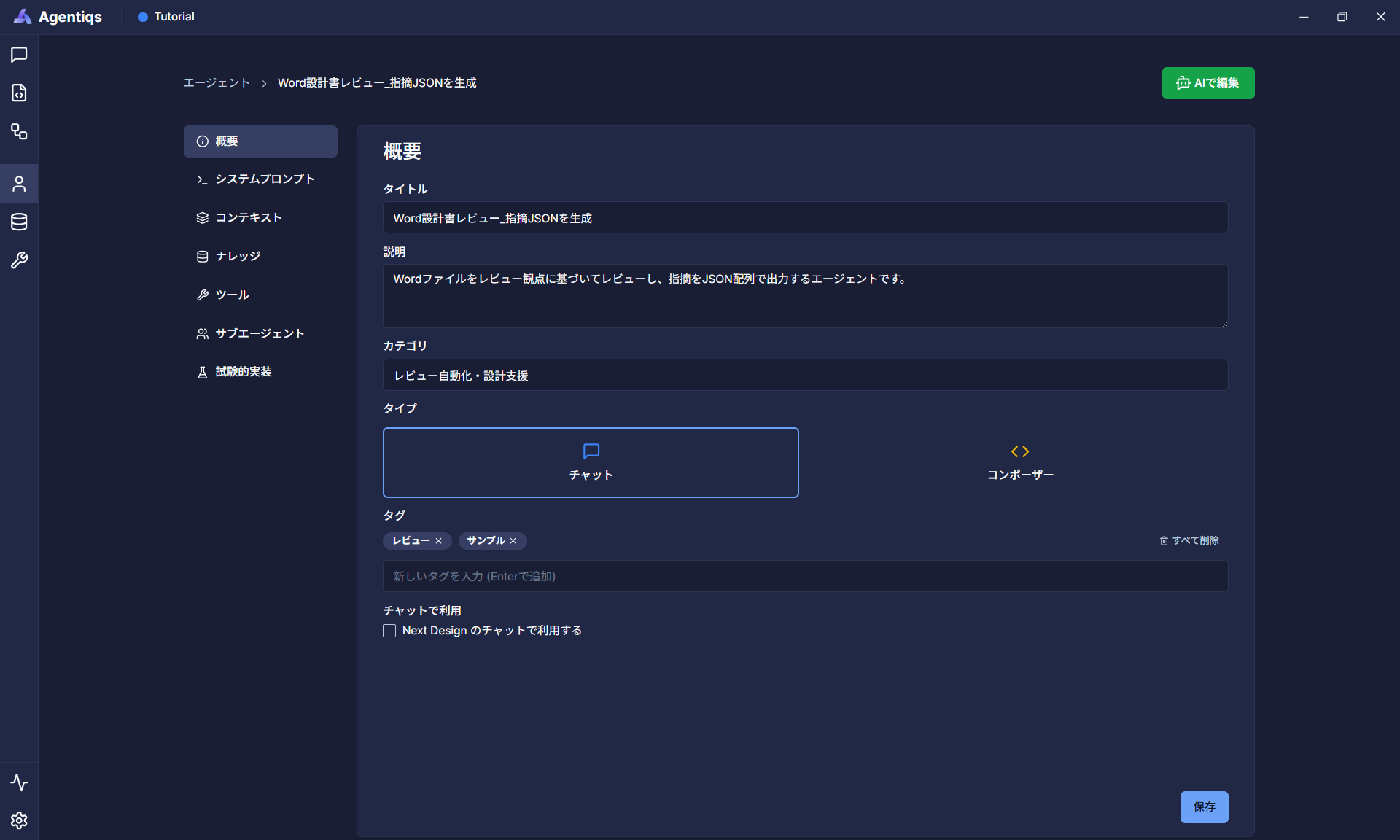
エージェントのプロパティ
プロパティ 必須 設定項目 詳細説明 タイトル 〇 「Word設計書レビュー_指摘JSONを生成」 後から判別できる、わかりやすい名前にしてください。 説明 エージェントの説明 システムプロンプト 〇 以下のコードを貼り付ける あなたは設計書レビュー専用エージェントである。入力された「設計書の1章分の内容」と「単一のレビュー観点」に対してレビューを実施し、結果をJSON配列のみで出力すること。【作業ステップ】1.入力のドキュメントの内容を理解する2.レビュー観点ごとに、レビューを実施し、指摘内容を検討する3.2で検討した内容を以下の # 出力ルール に従ってJSON形式で出力する# 出力ルール・出力はJSON配列のみとし、それ以外の文字列は出力しない。・各要素は以下のキーを必ず含むこと。- "location": 該当箇所を具体的に記載する。章、節、項、図表、ページなど、特定可能な範囲を含める。- "description": 指摘内容を記載する。何が不足・不整合・不明確かを明示する。指摘はですます調で統一し、読みやすいように改行をいれること。指摘がない場合は「<指摘なし> 確認済み・問題なし」とする。- "viewPoint": 入力のreview_pointのTitleを設定する。- "priority": "高" / "中" / "低" のいずれかのみ。- "status": 指摘ありは "Open"、指摘なしは "Closed"。・キー名は固定とし、値はすべて文字列とする。・review_point のみを基準に判定し、それ以外の観点で指摘しない。・chapter_info に記載された事実のみを根拠に判断し、推測しない。・該当箇所が見当たらない場合も、その事実を根拠に結果を出力する。【判定ルール】- review_point に照らして、記載不足、矛盾、不整合、不明確さ、不備が確認できる場合は指摘ありとする。- review_point に照らして問題が確認できない場合は"<指摘なし>"を出力する。- 判定に必要な情報が不足している場合は�指摘ありとし、不足内容をdescriptionに具体的に記載する。【出力件数】- review_point に対して複数の独立した問題がある場合は複数件出力すること。- 問題が1件もない場合でも、"<指摘なし>"を1件出力すること。【入力】- chapter_info: レビュー対象の章内容【レビュー観点】:review_pointID1:【異常系処理】 内容:外部/内部の入力データや受信データが無効(途切れ・誤動作・チャタリング等を含む)となった場合に、無効検知方法、前回有効値の保持・無視・安全なデフォルト値への遷移、制御状態/出力の扱い、エラー処理手順を含めたシステム応答方針が仕様・設計として具体的に定義されているかを確認する。ID2:【フ��ェイルセーフ・安全性】 内容:信号の誤動作を含む入力異常が発生した場合に、安全性を確保するためのフェイルセーフ方針(安全側への制御、機能継続可否、制限動作の考え方)が仕様として明示されているかを確認する。ID3:【初期値・保持・リセット】 内容:システム/コンポーネント起動時に実施する初期化処理の内容と各項目の初期値が具体的に記載されているか、また起動時に初期化すべき項目と再起動後も前回値として保持・永続化すべき項目が区分され、その扱い(初期化範囲)が仕様・設計として明確に定義されているかを確認する。 -
AIエージェントの作成が完了したら、作成したAIエージェントをワークフローで呼び出し、ユーザーメッセージを設定します。
"AIエージェント"をドラッグ&ドロップで配置し、プロパティを設定してください。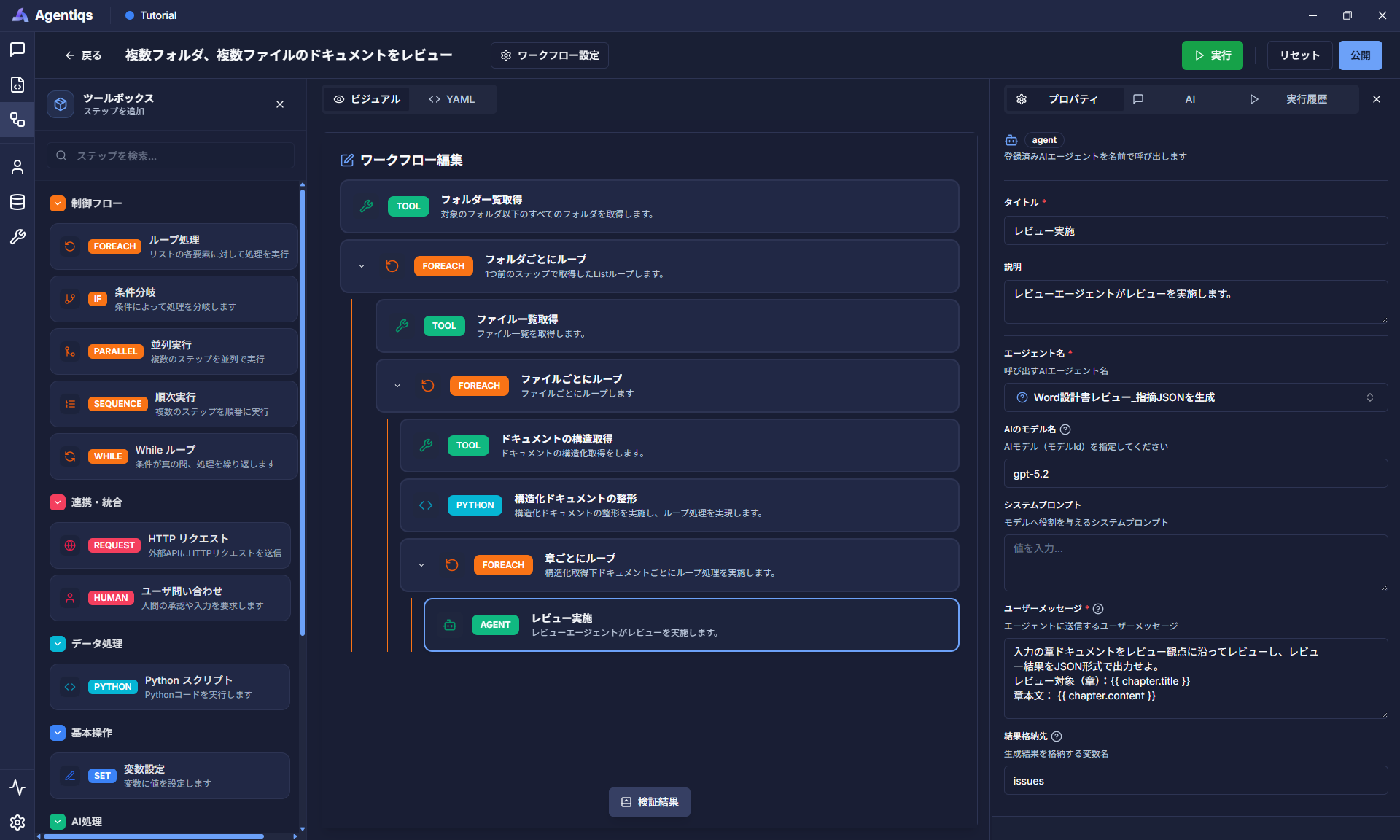
プロパティの設定項目
「Word設計書レビュー_指摘JSONを生成」エージェントに入力情報(レビュー対象の章、本文)を与え、レビューを実施します。
プロパティ 必須 設定項目 詳細説明 タイトル タイトル 後から判別できる、わかりやすい名前にしてください。 説明 ステップで実施する内容 エージェント名 〇 "Word設計書レビュー_指摘JSONを生成" 手順12で設定したAIエージェント名です。 AIのモデル名 〇 gpt5.2 利用するAIモデルを指定します。 システムプロンプト 記載無し 今回はAIエージェントの作成画面で定義しているため不要です。 ユーザーメッセージ 〇 以下の記載を貼り付ける 結果格納先 〇 issuesユーザーメッセージの内容:
入力の章ドキュメントをレビュー観点に沿ってレビューし、レビュー結果をJSON形式で出力せよ。レビュー対象(章):{{ chapter.title }}章本文: {{ chapter.content }} -
レビューエージェント呼び出し結果を変数に格納します。
先に格納しておく内部変数を[ワークフロー設定] - [内部変数]から、図のように設定してください。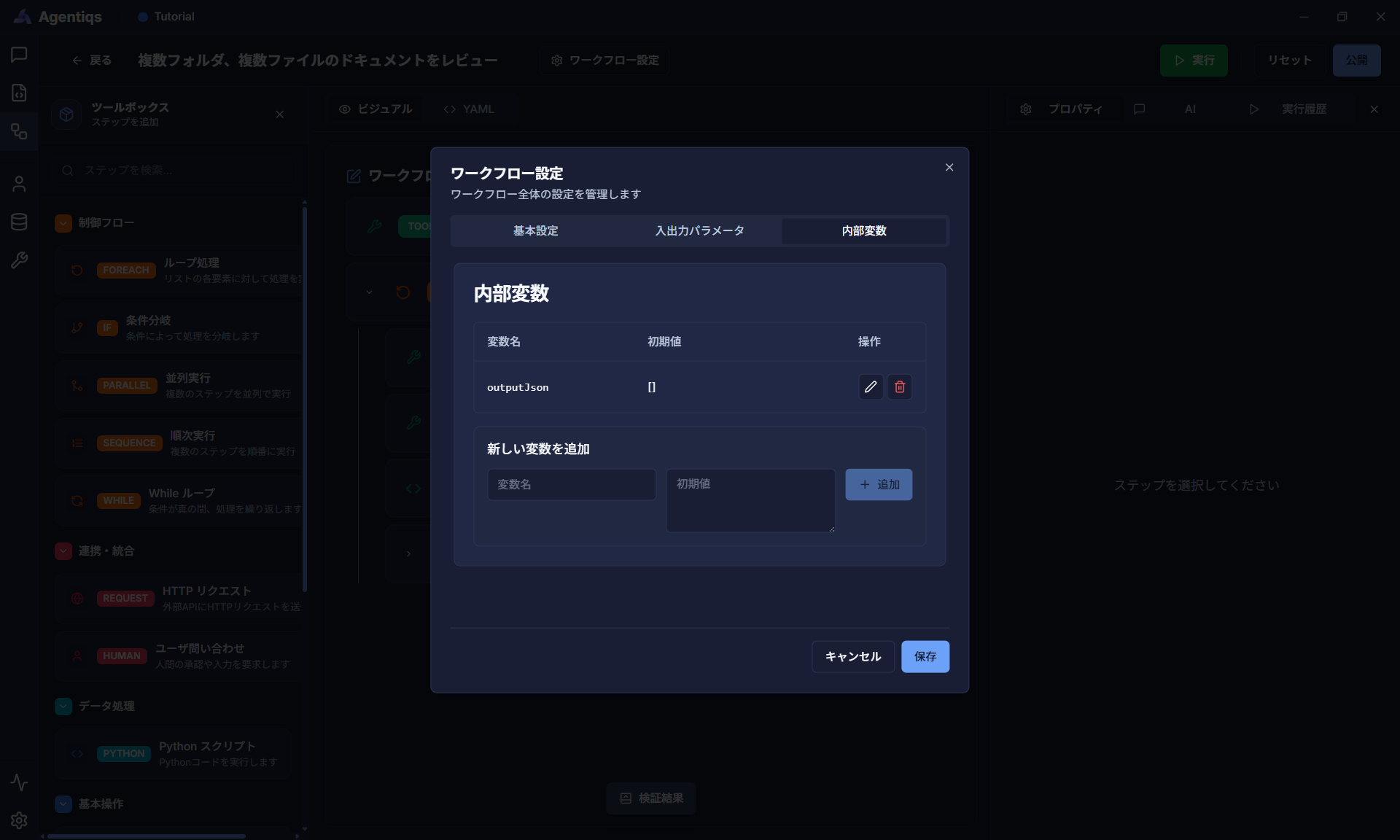
-
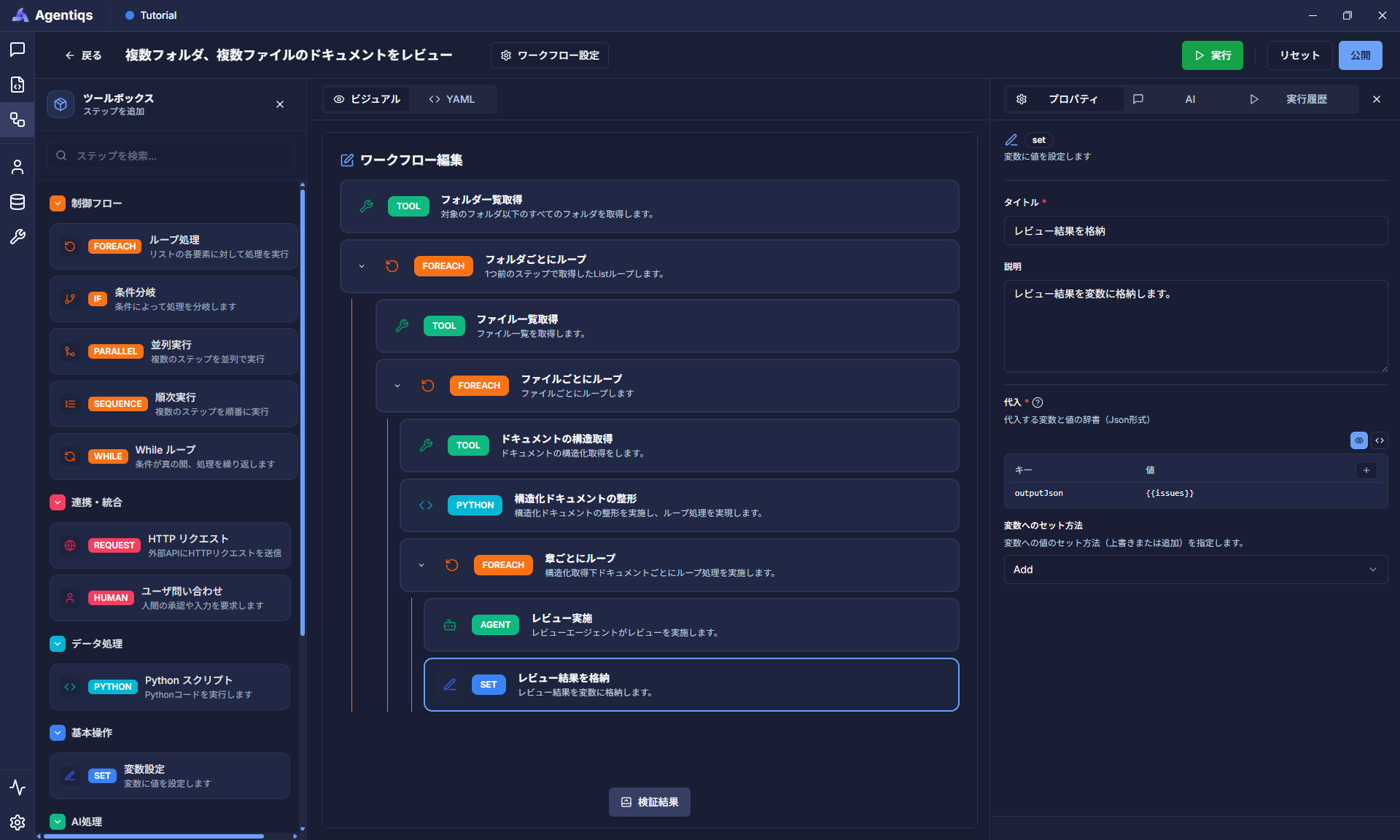
"変数設定"をドラッグ&ドロップで配置し、画像の通り、プロパティを設定します。
注記"変数への設定方法"は、Addを指定してください。
 ヒント
ヒント代入する
{{issues}}には、前のステップでAIエージェントがレビューした結果が入っています。 -
最後にレビュー結果を出力します。
今回はサンプルとして、2通りの方法で出力します。
本番環境での利用時は、ユーザー様の用途に合わせて、エージェントやツール呼び出しで任意に出力してください。-
方法1:JSON形式でそのまま出力する場合
画像の通り、"ツール実行"を配置し、プロパティを設定します。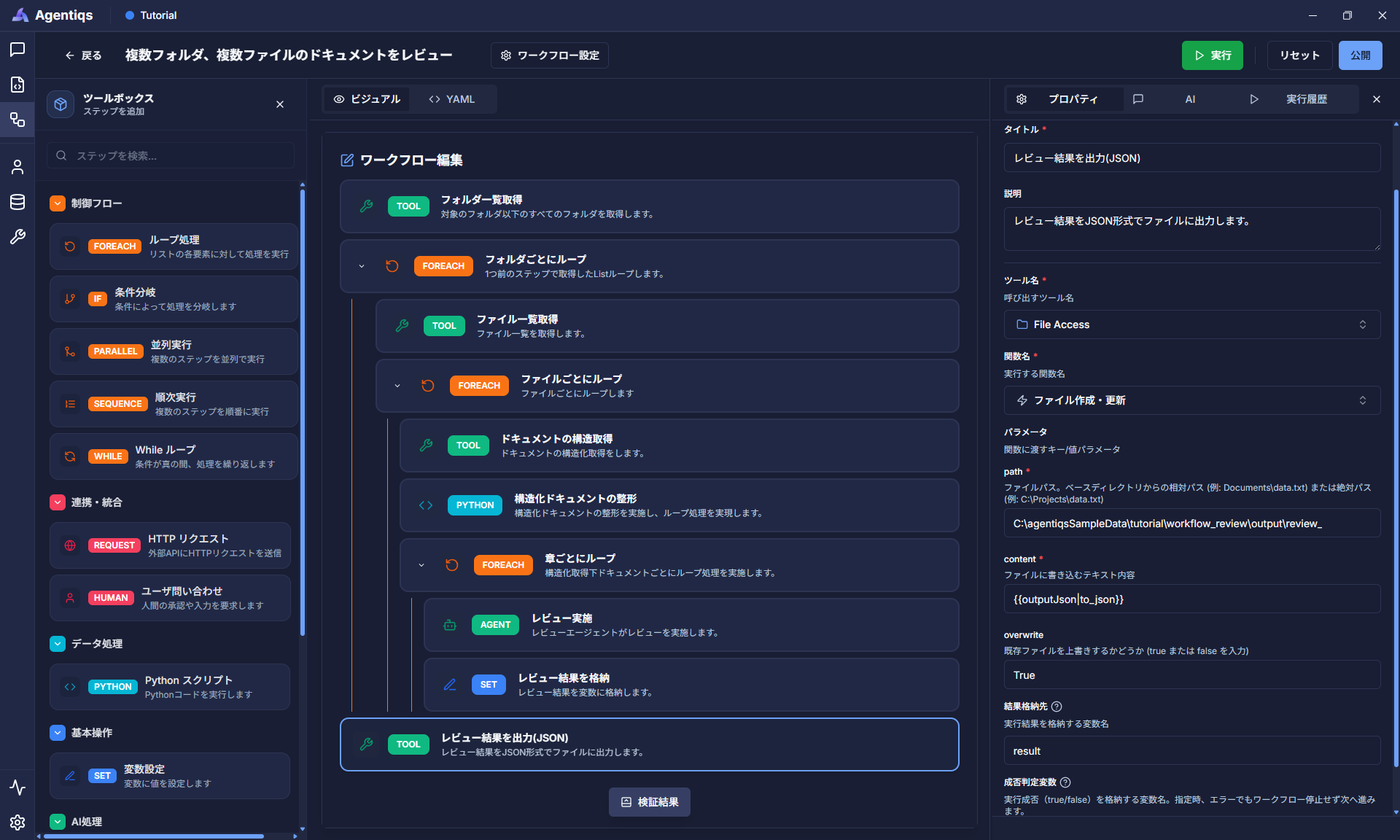
プロパティの設定項目
前のステップで設定した変数の内容を 「Path」で指定したファイルに出力します。
プロパティ 必須 設定項目 詳細説明 タイトル 後から判別できる、わかりやすい名前にしてください。 説明 ステップで実施する内容 ツール名 〇 手順3で作成したツール 関数名 〇 「ファイル作成・更新」 Path 〇 ※のパス 任意の場所を設定してください。 content 〇 {{outputJson|to_json}}出力するテキスト情報を定義します。 ※
C:\agentiqsSampleData\tutorial\workflow_review\output\review_result.json -
方法2:Excelに表として出力する場合
以下の2つのステップで、AIエージェントにJSONデータをExcelへ出力させます。【Step1】まずはAIエージェントを作成します。
[エージェント]タブ [新規作成] - [空のエージェント]からシステムプロンプトやツール選択を設定します。エージェントのプロパティ
指摘の内容をExcelに表形式で一覧にして出力するエージェントを作成します。
プロパティ 必須 設定項目 詳�細説明 タイトル 〇 「レビュー結果Excel生成」 後から判別できる、わかりやすい名前にしてください。 説明 エージェントの説明 システムプロンプト 〇 ※1のコードを貼り付ける ツール 〇 Excelツールを選択 ※2の画像のように使用する機能をONにします。 ※1 システムプロンプト
【目的】- JSON形式で提供されるレビュー指摘の情報を、アクティブなExcelファイルに出力すること。- 出力されたExcelは、指摘の内容を詳細かつ視覚的に分かりやすく提供する。【作業ステップ】1.指摘情報を把握する2.Excelへ1の情報を表として転記する【入力】- 下記の要素をもったJSON配列- 該当箇所(章・節・図表・ページの情報)- 指摘内容(問題点の詳細)- レビュー観点(レビューの基準)- 優先度(高/中/低)- ステータス(Open/対応中/Closed)【出力】- アクティブなExcelファイルに、「レビュー指摘」シートに内容を出力する。シートがない場合はシートを作成する。- 先頭行にはJSON配列の要素名をヘッダ行として出力し、ヘッド行と分かるように色を変える。(グレー以外)- 指摘ごとに行を作成する。- 罫線を入れて表として体裁を整えること。※2 Excelツールの設定(拡大する場合は画像を右クリックして新しいタブで開いてください。)
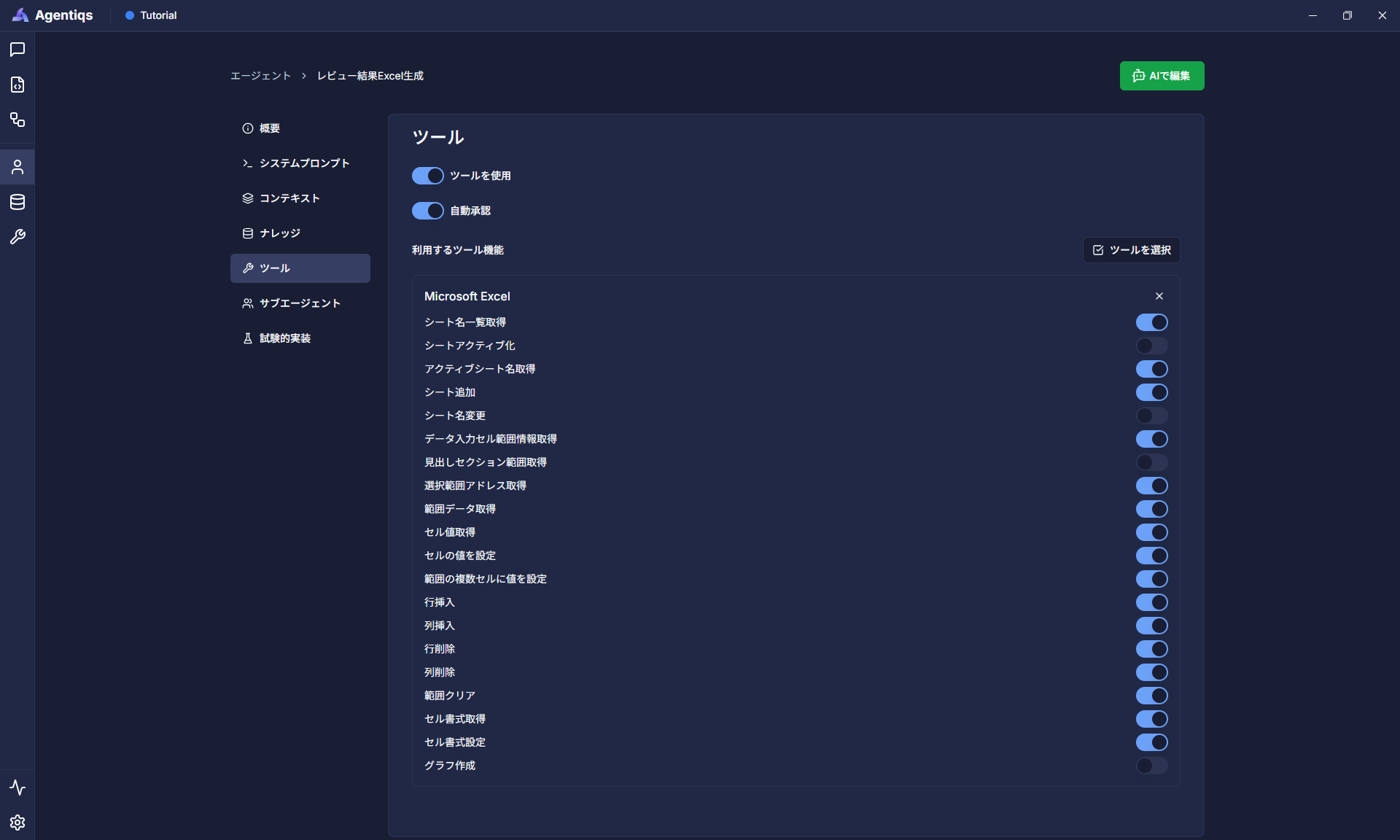
【Step2】作成したAIエージェントをワークフローで呼び出し、ユーザーメッセージを設定します。
"AIエージェント"をドラッグ&ドロップで配置し、プロパティを設定します。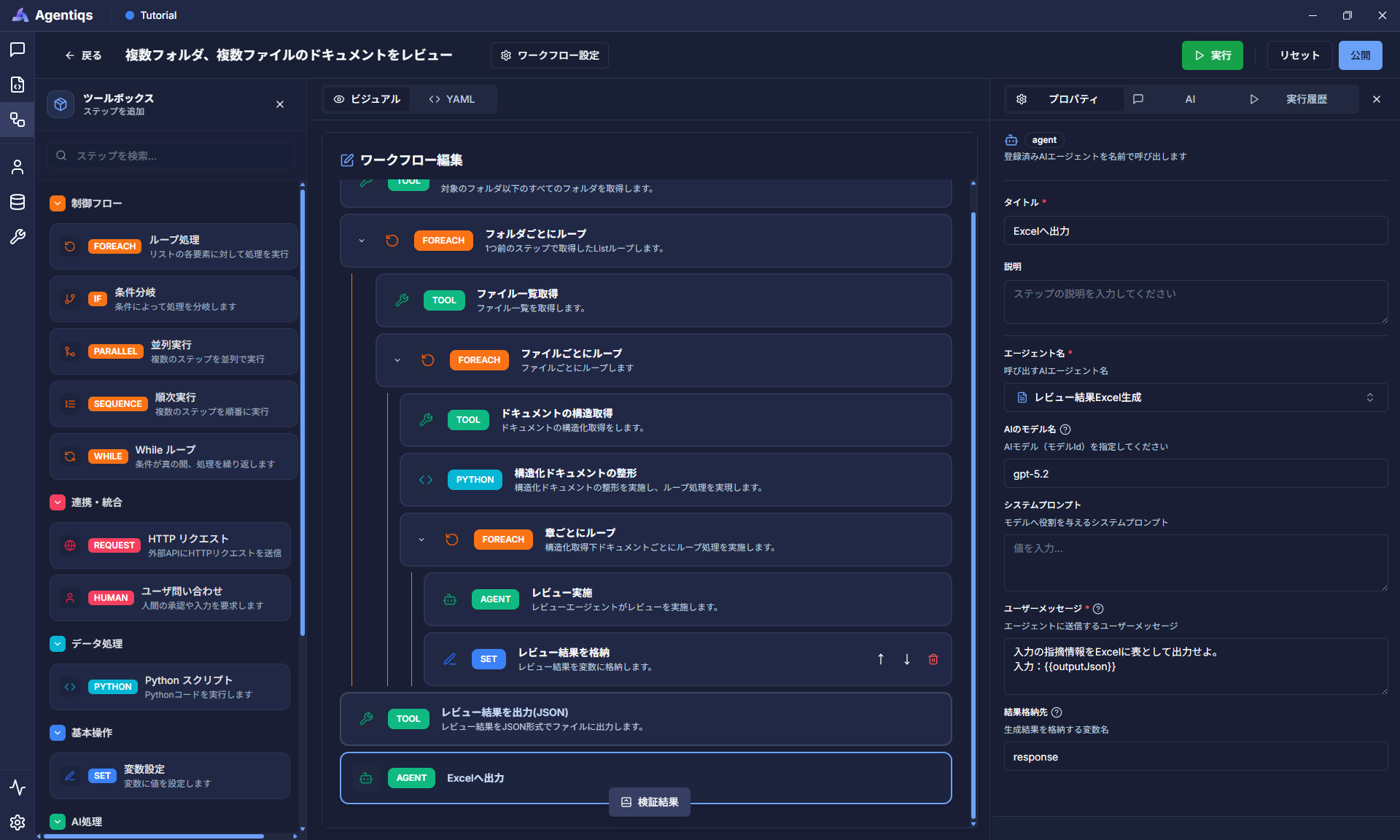
プロパティの設定項目
【Step1】で作成したAIエージェントを呼び出し、実際にファイルに出力します。
プロパティ 必須 設定項目 詳細説明 タイトル タイトル 後から判別できる、わかりやすい名前にしてください。 説明 ステップで実施する内容 エージェント名 〇 "レビュー結果Excel生成" Step1で設定したAIエージェント名です。 AIのモデル名 〇 gpt5.2 利用するAIモデルを指定します。 システムプロンプト 記載無し 今回はAIエージェントの作成画面で定義しているため不要です。 ユーザーメッセージ 〇 以下の記載を貼り付ける ユーザーメッセージの内容:
入力の指摘情報をExcelに表として出力せよ。入力:{{outputJson}}
-
2. ワークフローを実行する
出来上がったワークフローを実行します。
手順16で結果の出力先にExcelを選択した場合は、ワークフローを実行する前に実行前にExcelを起動してください。
ワークフロー右上の「実行」ボタンをクリックしてください。
よくあるトラブル
Json の変換エラー
AIエージェントによる JSON形式の出力では、場合によって Markdown形式でJSONを出力する等、エラーが発生する場合があります。
JSON形式の変換でエラーが発生する場合は、文字列でも対処できるように、スクリプトでフェイルセーフにします。
以下のpythonスクリプトを画像の通り、レビューエージェントの間に追加することによって抑えることができます。
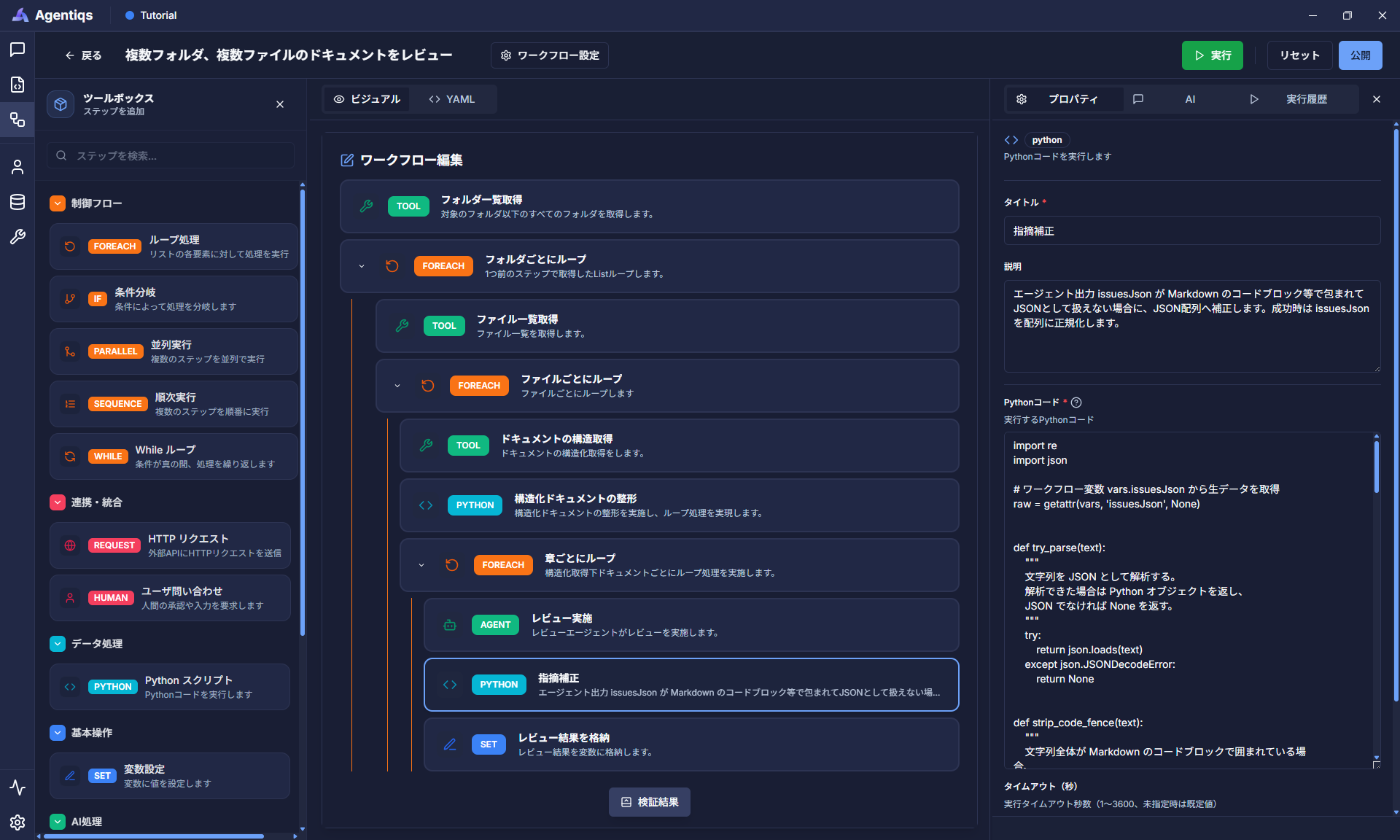
プロパティの設定項目
AIやワークフローの前工程から返ってきた文字列を、JSON配列に変換します。
(一部形式が壊れているケースがあるため)
| プロパティ | 必須 | 設定項目 | 詳細説明 |
|---|---|---|---|
| タイトル | タイトル | 後から判別できる、わかりやすい名前にしてください。 | |
| 説明 | ステップで実施する内容 | ||
| Pythonコード | 〇 | 以下のコードを貼り付ける |
import re
import json
# ワークフロー変数 vars.issues から生データを取得
raw = getattr(vars, 'issues', None)
def try_parse(text):
"""
文字列を JSON として解析する。
解析できた場合は Python オブジェクトを返し、
JSON でなければ None を返す。
"""
try:
return json.loads(text)
except ValueError:
return None
def strip_code_fence(text):
"""
文字列全体が Markdown のコードブロックで囲まれている場合、
先頭の ```json / ``` と末尾の ``` を除去する。
"""
if text is None:
return text
text = text.strip()
# 文字列全体がコードフェンスで囲まれている場合のみ除去する
fence = re.compile(
r'^\s*```(?:json)?\s*([\s\S]*?)\s*```\s*$',
re.IGNORECASE
)
m = fence.match(text)
return m.group(1).strip() if m else text
def strip_wrapping_quotes(text, max_times=2):
"""
文字列全体を囲う余計な引用符を除去する。
例:
'"[...]"' -> '[...]'
"'[...]'" -> '[...]'
二重に囲まれているケースもあるため、最大 max_times 回まで繰り返す。
"""
s = text.strip()
for _ in range(max_times):
if len(s) >= 2 and (
(s[0] == '"' and s[-1] == '"') or
(s[0] == "'" and s[-1] == "'")
):
s = s[1:-1].strip()
else:
break
return s
# すでに Python の list なら、そのまま採用する
if isinstance(raw, list):
vars.issues = raw
else:
# None の場合は空文字にして以降の処理を統一
s = '' if raw is None else str(raw)
s = s.strip()
# 1. Markdown のコードブロックを除去
s = strip_code_fence(s)
# 2. 文字列全体を囲う余計な引用符を除去
s = strip_wrapping_quotes(s)
# 3. まずはそのまま JSON パースを試す
parsed = try_parse(s)
# 4. パースできない場合、
# \n や \" を含む「エスケープされた JSON文字列」を想定して復元を試す
if parsed is None:
try:
# 例: "[{\"a\":1}]" のような文字列を復元するための救済処理
s2 = bytes(s, 'utf-8').decode('unicode_escape')
except UnicodeDecodeError:
# 復元に失敗した場合は元の文字列を使う
s2 = s
s2 = strip_code_fence(s2)
s2 = strip_wrapping_quotes(s2)
parsed = try_parse(s2)
else:
s2 = s
# 5. まだパースできない場合の最後の救済:
# テキスト中から最初の JSON 配列らしき部分を抜き出して再試行する
if parsed is None:
for candidate in (s2, s):
start = candidate.find('[')
end = candidate.rfind(']')
if start != -1 and end != -1 and end > start:
parsed = try_parse(candidate[start:end + 1])
if parsed is not None:
break
# 6. 最終的に JSON として読めなければエラー
if parsed is None:
raise Exception(
'issues を JSON として解析できませんでした。出力の形式を確認してください。'
)
# 7. 想定どおり JSON 配列であることを確認
if not isinstance(parsed, list):
raise Exception('issues は JSON配列である必要があります。')
# 8. 正常に解析できた結果を vars.issues に格納
vars.issues = parsed
FileAccessエラー
今回利用しているFileAccessツールは、ツールの設定側でベースディレクトリを設定しています。
input/outputのフォルダやファイルがFileAccessツールで設定しているベースディレクトリの配下にない場合、エラーになります。
ベースディレクトリの設定を再度確認してください。
ワークフローを活用するポイント
デバッグ
実行の途中に出力結果を確認する
ワークフロー実行中の任意のステップで、途中の出力結果を確認したい場合は、「HUMAN:ユーザー問い合わせ」配置してください。
ワークフローの中で使用する変数の値を、ダイアログに表示し、都度確認することができます。
実行途中の結果を外部に出力する
実行履歴からでは、正確に途中経過を確認できません。
出力したい変数を、FileAccessツール、ファイル出力を利用して、予め処理の内容をログファイルに出力するように設定してください。